Schema Scripts
Overview
Schema Scripts is a mechanism used during the Matrix42 system installation and update.
Schema Scripts are intended for the Database Layer of the entire Matrix42 system as a way of creating, modifying and deleting:
- table structure elements of the relational database;
- data objects and records of the existing tables.
Schema Scripts are applied for:
- Standard applications: enables the distribution of the business components and modules integration into the application. Schema scripts of the standard applications are implemented by the in-house developers of the Matrix42 platform.
- Custom applications: allows distributing custom components created on the basis of the standard application. As a rule, custom packages can be generated by the application administrators within those organizations that run business processes via Matrix42 platform.
- Configuration Packaging: a low-code development platform (LCDP) that provides development capabilities where multiple users can work on various projects and create application software through graphical user interfaces with Configuration Packaging technology.
All Schema Scripts are located in the /Config/ software distribution directory.
Creating Schema Scripts
Matrix42 SchemaViewer
SchemaViewer is a multi-purpose toolkit for such administrative tasks as schema and data consistency check, generating schema extensions by scripting, and many other features:
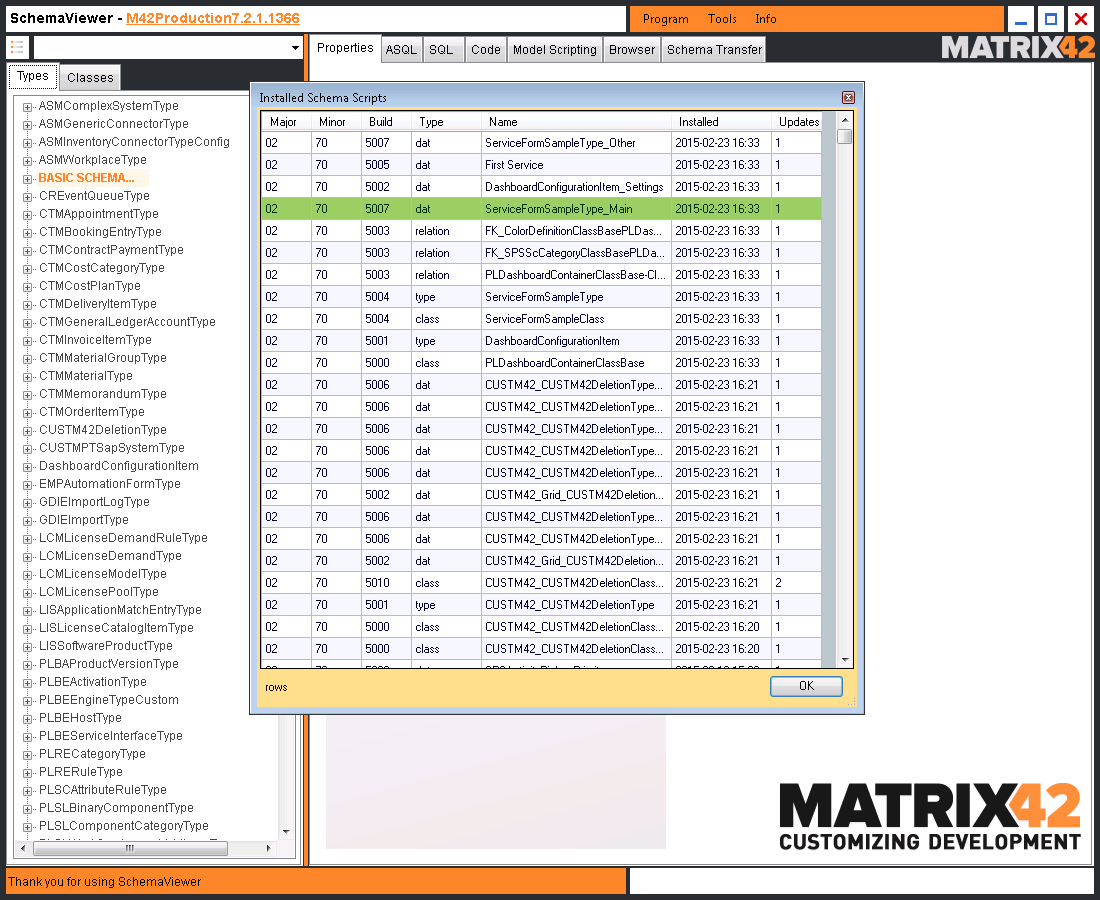
For more detail see Matrix42 Marketplace: SchemaViewer.
Manually
Some script types cannot be generated by the system and require manual coding, for instance, .bin scripts.
Manually created scripts are used in rare and complex cases when the automatically generated scripts do not cover the necessary data changes in the system or it is necessary to update or delete the system data, that cannot be changed via the application's user interface. Most often used cases like standard structured data update or schema modification is covered by the Record Customization functionality, which is available in the Administration application.
Command line: data import/export
- Run schemaEL file from the application’s root directory in the command line, for example:
/Matrix42 Workplace Management/bin/SchemaEL.exe
2. Use available commands for data import/export.
schemaEL allows exporting the entire schema file or data of a specific object type. It does not keep track of the applied to the system changes.
User interface: data export
Schema scripts that create data (.dat) and delete data (.del) can be automatically generated from any application that has data objects listed in the grid. Data can be downloaded by users who have access to "Export" action.
Export action allows generating the following types of schema scripts:
a. XML structured file has .dat extension. Generated schema script allows creating data based on the exported items.
b. Delete statements generates .del schema scripts. Generated script exports information about the data objects that will be removed from the database when the script is run, whilst the data itself remains in the application intact.
Generated scripts do not have automatically assigned script version.
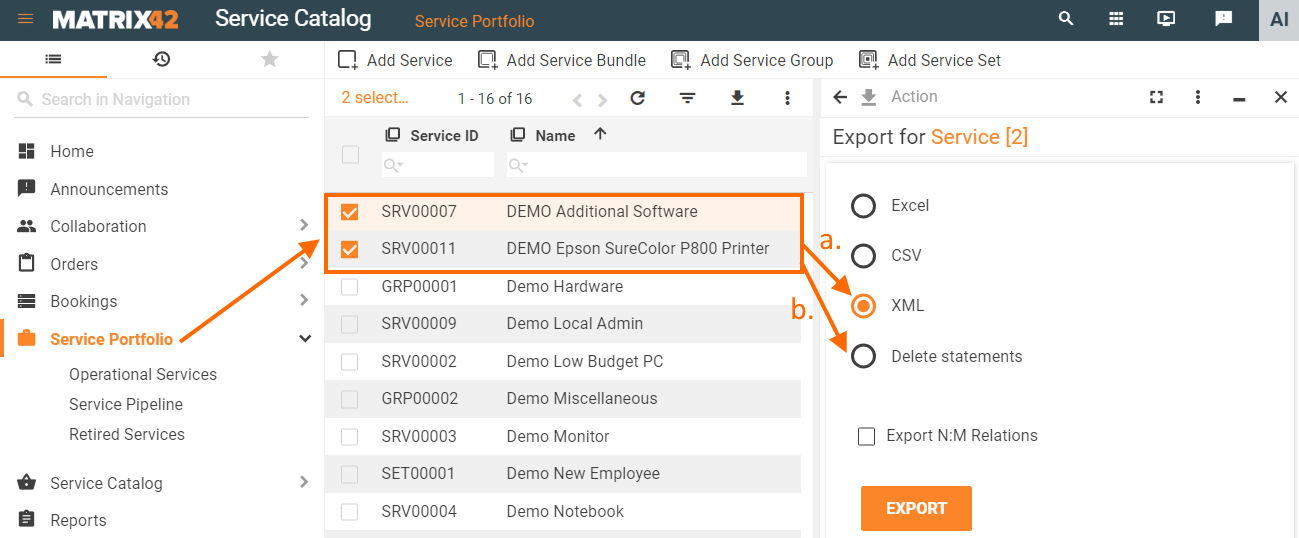
Generating schema scripts: data objects export
Automatically generated schema scripts
The easiest, quickest, and least error-prone way to generate schema scripts is to do it automatically. The system allows to do so with default-available Record Customization functionality or with additionally installed Configuration Packaging extension that provides a rich user interface for the schema scripts recording and managing.
Follow these steps to automatically generate and export schema scripts via Record Customization:
- Start Recording: in Administration application → Home page → click Start Recording:
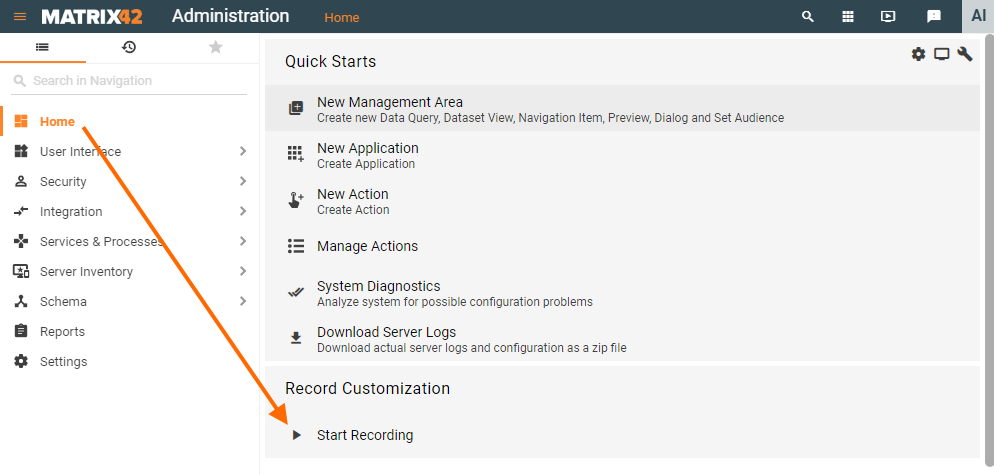
- Introduce changes via user interface: create, delete, or modify data or data structure as necessary. The system tracks all data changes and generates schema scripts of a specific type according to the data changes.
- Export generated Schema Scripts: in Administration application → Home page → click Download distribution package:
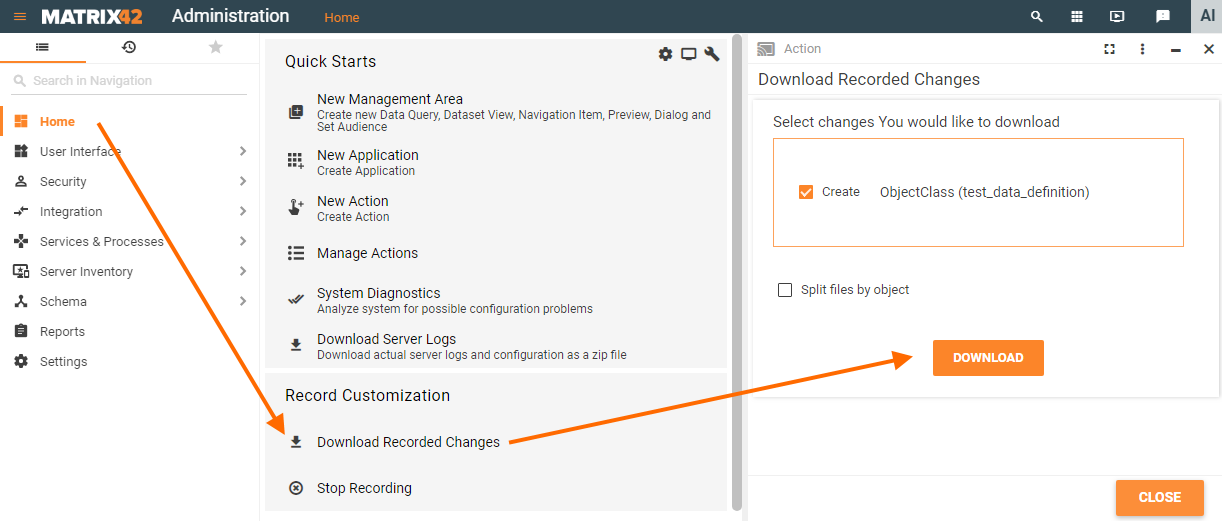
Split files by object checkbox defines how the data-related scripts are generated. These are .post, .dat, and .del scripts automatically generated as a result of corresponding data operations (create, update, and delete data objects). Schema-related changes are always generated as stand-alone schema scripts for each schema element and each specific data operation.
The Split files by object option affects automatic script generation for each type of data operation as follows:
- by default, Split files by object checkbox is disabled. As a result, when creating several data objects during the running Record Customization the data changes are listed in a single .post script.
- enabled Split files by object checkbox option allows exporting all data object changes as stand-alone scripts. For instance, when adding several Navigation Items the .post script is generated for each added to the system data object.
- Stop Recording: download the recorded changes and click Stop Recording. You will not be able to download recorded changes afterward.
- Manually upload scripts to the necessary application of the /Config/ directory and apply all necessary changes to the list of running scripts according to their usage and purpose (either intended for application installation or update, scripts are extending the standard Matrix42 platform or were created as a customization package of a basic platform according to a particular organization’s needs and requirements. For more detail see Schema Scripts integration section).
Record Customization generates schema scripts of appropriate type with corresponding data according to the performed in the user interface actions. Script versions are assigned automatically, version numbers are incremented automatically as well.
Schema scripts
Basic overview
Each Schema Script is a file that has a type, a file version, a standardized format, and is designed to operate with particular data of the application's Data Layer. Schema Scripts are run in a specific order defined by the script version and type:

The table below covers the basic principles of the schema scripts, with a few reservations:
- Scripts running sequence is applied when the scripts have identical versions.
- Type column lists the most frequently used script types. The type is distinguished by the file extension. Other script types that are not mentioned should be considered as obsolete.
- Script generation is applicable for those data objects and application schema which are not a part of system data and are generated by the Record Customization functionality.
| Scripts running sequence |
Type |
Operated data |
Operations |
Format |
Script generation |
||
|---|---|---|---|---|---|---|---|
| Create | Update | Delete | |||||
| 1 |
.pre |
database table structure and data (running scripts for preliminary preparation of the basic database structure and data) |
✔️ | ✔️ | ✔️ |
SQL |
Manually |
| 2 |
.tab |
database table structure and data (e.g. creating SchemaScripts table) |
✔️ | ✔️ | ✔️ |
SQL |
Manually |
| 3 |
.sql |
database table structure and data (intermediate scripts applying necessary changes after preliminary database setup but before running the main part of the schema scripts) |
✔️ | ✔️ | ✔️ |
SQL |
Manually |
| 4 |
.pickup |
Data Definitions of a Pickup type |
✔️ | ✔️ | ✔️ |
XML |
Automatically |
| 5 |
.class |
Data Definitions of a Class type |
✔️ | ✔️ | ✔️ |
XML |
Automatically |
| 6 |
.relation |
class attributes relations |
✔️ | ✔️ | ✔️ |
XML |
Automatically |
| 7 |
.type |
Configuration Items. |
✔️ | ✔️ | ✔️ |
XML |
Automatically |
| 8 |
.dat .loc .merge .update |
data objects and records of the Classes .loc files contain localization string data objects and records of the Classes. |
✔️ | ✔️ | ❌ |
XML |
Automatically |
| 9 |
.del |
data objects and records of the Classes |
❌ | ❌ | ✔️ |
XML |
Automatically |
| 10 |
.bin |
|
✔️ | ✔️ | ✔️ |
XML |
Manually |
| 11 |
.post |
data objects and records of the Classes |
❌ | ✔️ | ❌ |
SQL |
Automatically |
Particularities
Schema Script files have the following characteristics:
- Version identifiers:
- Major: the value of the major version should always be Major=”2”. Do not modify it manually for the newly added files;
- Minor: minor version;
- Build: the version of the build that can be manually modified if the automatically assigned version may lead to the data collision;
- Type: file/script type. The type defines which kind of data will be applied to the database and which type of data operation is run (create, update, delete);
- Name: unique name within the current version. The name of the file does not affect the order of the run scripts. The file name describes the gist of the file data and performed data operation;
- FilePath: indicates where the actual file is located.
Assigning version
- Automatically: Record Customization automatically generates the appropriate version for the script;
- Manually: for the manually created script search for the latest version of the modified application's .XML file and increase the build version by 1 and assign it to the created script.
Schema script types
Data Definitions management
Pickup
.pickup file stores the description of the pickup attributes in XML format. A pickup is a Data Definition represented in the database as a table with attributes.
In a creation script, the type of class is mandatory. Pickup class type is 4:
<ClassType>4</ClassType>
Each pickup file is always accompanied by a .dat file which holds the data of a pickup, the actual values of the attributes (values of the drop-down list).
Created .pickup along with the .dat file creates options of the drop-down list which are further used in the .class as an attribute of a class.
Class
.class scripts allow creating, modifying and deleting the structure elements of the class. Stores the description of the class attributes in XML format.
A class is a Data Definition represented in the database as a table with attributes.
.class script:
- is created as a stand-alone file;
- has the same structure as a .pickup file;
- does not include attribute relations;
- classType=3;
- can depend on a pickup (have pickup as an attribute) so it’s executed after the .pickup.
.class script example for creating Data Definition:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<NewDataSet>
<BasicSchemaObjectClass>
<ID>f0309578-b286-e911-f280-00505690f39d</ID>
<Name>Ud_custom</Name>
<IsSchemaObject>0</IsSchemaObject>
<DisplayName>Custom Data Definition</DisplayName>
<ProtectionLevel>4</ProtectionLevel>
<ClassType>3</ClassType>
<DisableHistory>1</DisableHistory>
</BasicSchemaObjectClass>
</NewDataSet>
Data Definition scripts structure
Creation script
A Data Definition creation script is a collection of properties a new item should have. Some of these properties are mandatory, some are optional.
Properties can also be collections of several items of the same type. Attributes in a Data Definition are an example of this, as a Data Definition can have more than one attribute. Other examples for such collections are localization for different languages or meta info.
Example
Example of a creation script for a Data Definition, with additional comments:
<?xml version="1.0" standalone="yes"?>
<NewDataSet>
<BasicSchemaObjectClass>
<!--Basic information needed to create a new data definition:-->
<ID>272ddf5e-1829-4041-b534-10b95084d96f</ID>
<Name>TestClass_2</Name>
<ClassType>3</ClassType>
<!--Optional additional information: -->
<Description>test</Description>
<!--Optional additional information in several sub-nodes:-->
<BasicSchemaObjectClass-CI>
<LCID>1031</LCID>
<Description>TestClass 1031</Description>
</BasicSchemaObjectClass-CI>
<BasicSchemaObjectClass-CI>
<LCID>1033</LCID>
<Description>TestClass 1033</Description>
</BasicSchemaObjectClass-CI>
<!--Basic information in several sub-nodes:-->
<BasicSchemaAttributeClass>
<!--Mandatory properties of a Data Definition attribute:-->
<ValueType>0</ValueType>
<ID>612cce70-41f3-47de-aa97-4ddf90f92584</ID>
<AllowNull>1</AllowNull>
<Name>StringAttribute</Name>
<!--Value type 0 is a string and needs an AttributeLength, so it is mandatory:-->
<AttributeLength>255</AttributeLength>
</BasicSchemaAttributeClass>
<BasicSchemaAttributeClass>
<ValueType>10</ValueType>
<ID>888bdb3f-bc6f-4036-8e99-10df1f3bdc5b</ID>
<AllowNull>1</AllowNull>
<Name>DecimalAttribute</Name>
<!--Value type 10 is a decimal and needs a Scale and a Precision node:-->
<Precision>8</Precision>
<Scale>4</Scale>
</BasicSchemaAttributeClass>
</BasicSchemaObjectClass>
</NewDataSet>
ClassType element
The type of the class is mandatory for creation scripts:
<ClassType>3</ClassType>
Allowed values and possible class types are:
- 3 custom class
- 4 pickup class
- 9 custom common class
- 10 view-based class
History settings
In a creation script, it is possible to define the history settings of the data definition:
<DisableHistory>1</DisableHistory>
Possible values:
- 0: enables creating records that keep track of the data changes of the specified Data Definition. Records are stored in a stand-alone database (by default in M42Archive);
- 1 (default): keep track of data changes in the archive database is disabled.
Schema protection level
Also, it is possible to define the schema protection level:
<ProtectionLevel>2</ProtectionLevel>
Possible values:
- 2: used for system schema elements that cannot be modified or deleted via the user interface. System data can be operated with a particular type of certificate, specified during the system installation process;
- 3: customizable protection level implies that there are system schema attributes that cannot be modified or deleted, but the schema can be extended with custom attributes;
- 4: custom protection level enables create, update and delete operations for all elements of the specified schema.
Optional elements
Optional elements can be specified for:
- the root node of the Data Definition;
- child nodes describing the attributes of the Data Definition.
Simple tags at the root node are:
<Description>test</Description>
<DisplayName>test</DisplayName>
Localization: the description and the display name can be localized:
<BasicSchemaObjectClass-CI>
<LCID>7</LCID>
<Description>Basis-Datendefinition für Konnektoren.</Description>
<DisplayName>Konnektor</DisplayName>
</BasicSchemaObjectClass-CI>
Meta info can be optionally defined as follows:
<Schema-MetaInfo>
<Value>Name</Value>
<Name>DisplayExpression</Name>
</Schema-MetaInfo>
Attribute nodes
More than one attribute node can be present. They must always contain an ID and name of the node:
<BasicSchemaAttributeClass>
<ID>612cce70-41f3-47de-aa97-4ddf90f92585</ID>
<Name>StringAttribute1</Name>
For the insert case the AllowNull and ValueType nodes are mandatory:
<AllowNull>1</AllowNull> <ValueType>0</ValueType>
Allowed values for the ValueType:
- 0 – string
- 1 – Guid
- 2 – int
- 3 – datetime
- 4 – long
- 5 – float
- 6 – blob
- 8 – text
- 9 – bool
- 10 – decimal
- 12 – bit
- 13 – varbinary
- 14 – short string
- 15 – currency
Additional information is required for such ValueTypes:
- String, Short string:
<AttributeLength>255</AttributeLength> - Decimal:
<Scale>4</Scale>
<Precision>8</Precision>
Attributes can have also a history disable node, protection level node and they can have the same optional nodes like the root node:
<NewDataSet>
<BasicSchemaObjectClass>
<ID>c6664bf2-276a-4969-9883-1fec5a4a6735</ID>
<Name>SPSAccountClassBase</Name>
<ActionOnImport>update</ActionOnImport>
<BasicSchemaAttributeClass>
<ID>6c28ee06-7e87-e911-fb80-005056908684</ID>
<Name>Ud_dismissalDate</Name>
<IsSchemaObject>0</IsSchemaObject>
<DisplayName>Dismissal Date</DisplayName>
<DisableHistory>1</DisableHistory>
<ProtectionLevel>4</ProtectionLevel>
<DataProtectionIgnored>0</DataProtectionIgnored>
<AllowNull>1</AllowNull>
<ValueType>0</ValueType>
<AttributeLength>100</AttributeLength>
<ActionOnImport>insert</ActionOnImport>
</BasicSchemaAttributeClass>
</BasicSchemaObjectClass>
</NewDataSet>
Update/Deletion Scripts
Example
Data Definition schema script example with additional comments:
<?xml version="1.0" encoding="UTF-8"?>
<NewDataSet>
<BasicSchemaObjectClass>
<!--Mandatory information to define the item to update:-->
<ID>317b058a-e612-483c-afa8-5909cb795dd4</ID>
<Name>BaseTest</Name>
<!-- What to do with the item on the root level; defines action on the level of the Data Definition:-->
<ActionOnImport>update</ActionOnImport>
<!--Simple update of optional information:-->
<BasicSchemaObjectClass-CI>
<LCID>1033</LCID>
<Description>Second</Description>
<!--What to do with the data of an item; mandatory element which defines action on the level of a Data Definition attribute:-->
<ActionOnImport>update</ActionOnImport>
</BasicSchemaObjectClass-CI
<!-- Deletion of information: -->
<BasicSchemaObjectClass-CI>
<LCID>1031</LCID>
<Description>First</Description>
<!--Mandatory element which defines the action on the sub-element level:-->
<ActionOnImport>delete</ActionOnImport>
</BasicSchemaObjectClass-CI>
<BasicSchemaAttributeClass>
<!-- Mandatory information to define the sub-item to update:-->
<Name>TestAttribute</Name>
<ID>afa48b2f-1029-43e2-a726-f1de2d82052f</ID>
<!--What to do with the sub-item-->
<ActionOnImport>update</ActionOnImport>
<!--Exact definition of the update action for the mandatory elements describing the attribute of the Data Definition
The list of available ActionOnUpdate values is provided below-->
<ActionOnUpdate>changeAllowNull</ActionOnUpdate>
<AllowNull>1</AllowNull>
</BasicSchemaAttributeClass>
</BasicSchemaObjectClass>
</NewDataSet>
ID and the Name of an item are mandatory data elements denoting which information will be updated by the script.
ActionOnImport element
ActionOnImport element defines the action on the existing item. Possible values:
- insert: if the tag is not present, “insert” is the default mode
- update
- delete
ActionOnImport tag is sufficient for the data changes in:
- optional properties
- localization
- Meta info
Can be specified for:
- the root node of the Data Definition if the change is applied to the basic elements of the Data Definition like changing the DisplayName of the Data Definition:
<NewDataSet> <BasicSchemaObjectClass> <ID>c6664bf2-276a-4969-9883-1fec5a4a6735</ID> <Name>SPSAccountClassBase</Name> <ActionOnImport>update</ActionOnImport> <DisplayName>User Account</DisplayName> </BasicSchemaObjectClass> </NewDataSet> - child nodes describing changes applied for the attributes of the Data Definition. The ActionOnImport update tag must be present on the root level as well. Also, the attribute must be qualified with its internal Name and ID:
<NewDataSet> <BasicSchemaObjectClass> <ID>c6664bf2-276a-4969-9883-1fec5a4a6735</ID> <Name>SPSAccountClassBase</Name> <ActionOnImport>update</ActionOnImport> <BasicSchemaAttributeClass> <ID>6c28ee06-7e87-e911-fb80-005056908684</ID> <Name>Ud_dismissDate</Name> <ActionOnImport>update</ActionOnImport> <DisplayName>Dismissal Date</DisplayName> </BasicSchemaAttributeClass> </BasicSchemaObjectClass> </NewDataSet>
ActionOnImport delete on the child nodes level deletes the attribute of the Data Definition:
<NewDataSet>
<BasicSchemaObjectClass>
<ID>c6664bf2-276a-4969-9883-1fec5a4a6735</ID>
<Name>SPSAccountClassBase</Name>
<ActionOnImport>update</ActionOnImport>
<BasicSchemaAttributeClass>
<ID>6c28ee06-7e87-e911-fb80-005056908684</ID>
<Name>Ud_dismissalDate</Name>
<ActionOnImport>delete</ActionOnImport>
</BasicSchemaAttributeClass>
</BasicSchemaObjectClass>
</NewDataSet>
ActionOnImport delete on the root node level deletes the entire Data Definition:
<NewDataSet>
<BasicSchemaObjectClass>
<ID>c6664bf2-276a-4969-9883-1fec5a4a6735</ID>
<Name>SPSAccountClassBase</Name>
<ActionOnImport>delte</ActionOnImport>
</BasicSchemaObjectClass>
</NewDataSet>
A history tracking change needs no action on update node, like the behavior on the root level:
<DisableHistory>1</DisableHistory>
ActionOnUpdate element
A set of specific data update actions require additional “ActionOnUpdate” tag used along with the “ActionOnImport” element.
ActionOnUpdate must be added for all other types of modified data, except for the optional properties, localization and Meta info.
ActionOnUpdate is specified for the types of actions that perform more complicated tasks on the database level like renaming or changing information type:
- Rename requires a node with the new name:
<ActionOnUpdate>rename</ActionOnUpdate>
<NewName>Description</NewName>
- Resize is valid for string attributes only; requires a node with the new size:
<ActionOnUpdate>resize</ActionOnUpdate>
<NewAttributeLength>200</NewAttributeLength>
- Null value behavior requires a node with the new value; disallow null fails if the attribute contains null values:
<ActionOnUpdate>changeAllowNull</ActionOnUpdate>
<AllowNull>1</AllowNull>
- Resize decimal is valid only for decimal attributes; requires nodes with the new scale and precision:
<ActionOnUpdate>resizeDecimal</ActionOnUpdate>
<NewAttributeScale>4</NewAttributeScale>
<NewAttributePrecision>12</NewAttributePrecision>
- Change to currency is valid only for decimal attributes with a scale of 4:
<ActionOnUpdate>changeToCurrency</ActionOnUpdate>
- Change to text is valid only for string attributes:
<ActionOnUpdate>changeToText</ActionOnUpdate>
- Change localization is valid only for string and text attributes; requires a node with the new value:
<ActionOnUpdate>languageDependent</ActionOnUpdate>
<LanguageDependent>1</LanguageDependent>
- Set Obsolete sets the Class or Type to obsolete, what prevents it from loading to Application (Data Layer), but still be present in Database:
<ActionOnUpdate>SetObsolete</ActionOnUpdate>
To reset Obsolete flag for Data Definition or Configuration Item adjust and apply the following SQL Script
declare @dd_name nvarchar(100), @class_id uniqueidentifier
set @dd_name = 'SPSTargetingQueryType'
UPDATE SchemaObjectClass
set Obsolete = 0
where Name = @dd_name
UPDATE SchemaObjectAttribute
set Obsolete = 0
where BelongsToSchemaObjectClass in (select ID from SchemaObjectClass Where Name = @dd_name)
UPDATE SchemaObjectRelation
set Obsolete = 0
where RightAttribute in (select ID from SchemaObjectAttribute where Obsolete = 0 and BelongsToSchemaObjectClass in (select ID from SchemaObjectClass Where Name = @dd_name)) or
LeftAttribute in (select ID from SchemaObjectAttribute where Obsolete = 0 and BelongsToSchemaObjectClass in (select ID from SchemaObjectClass Where Name = @dd_name))
Relation
Defines and creates relations of the Data Definition attributes.
Type
Defines and creates the Configuration Item.
Configuration Item contains Data Definitions, so the .type script should be run after the .class, containing the description of the attributes:
<NewDataSet>
<BasicSchemaObjectType>
<ID>e8582113-d486-e911-f280-00505690f39d</ID>
<Name>Ud_</Name>
<IsSchemaObject>0</IsSchemaObject>
<Schema-MetaInfo>
<Name>ArchivingEnabled</Name>
<Value>False</Value>
</Schema-MetaInfo>
<Schema-MetaInfo>
<Name>AddActionPosition</Name>
<Value>0</Value>
</Schema-MetaInfo>
<Schema-MetaInfo>
<Name>UseUserCurrency</Name>
<Value>False</Value>
</Schema-MetaInfo>
<Schema-MetaInfo>
<Name>StateGroup</Name>
<Value>0</Value>
</Schema-MetaInfo>
<Schema-MetaInfo>
<Name>UUXColor</Name>
<Value>#a30b35</Value>
</Schema-MetaInfo>
<Schema-MetaInfo>
<Name>DisplayExpression</Name>
<Value>name</Value>
</Schema-MetaInfo>
<DisplayName>New CI</DisplayName>
<ProtectionLevel>4</ProtectionLevel>
<BasedOnTypeClass>184e1215-b1fe-4bcd-9fc6-70035a33a4f3</BasedOnTypeClass>
<BasicSchemaObjectTypeToClass>
<RelatedSchemaObjectClass>856166c0-1e29-e311-3782-001f81000830</RelatedSchemaObjectClass>
<Cardinality>0</Cardinality>
<ProtectionLevel>0</ProtectionLevel>
</BasicSchemaObjectTypeToClass>
</BasicSchemaObjectType>
</NewDataSet>
Configuration items are represented in the database by related tables that have a common foreign key. They have a name, ID, and contain a collection of data definitions composing the CI. The DDs that are part of the composition have a defined cardinality in the CI; this cardinality is part of the CI definition. The ID and name are always mandatory if you want to create or change a CI.
Root elements
Every .type must start with these nodes:
<NewDataSet>
<BasicSchemaObjectType>
<ID>9226486b-d7f0-4fd0-b667-da14a2a11487</ID>
<Name>TestType</Name>
It is possible to define the schema protection level:
<ProtectionLevel>2</ProtectionLevel>
Optional elements
Optional simple tags at the root node are:
<Description>test</Description>
<DisplayName>test</DisplayName>
Localization: the description and the display name can be localized:
<BasicSchemaObjectType-CI>
<LCID>7</LCID>
<Description>CI für Konnektoren.</Description>
<DisplayName>Konnektor</DisplayName>
</BasicSchemaObjectType-CI>
Meta info: optionally, you can define Meta info for the Configuration Item:
<Schema-MetaInfo>
<Value>Name</Value>
<Name>DisplayExpression</Name>
</Schema-MetaInfo>
Related Classes nodes
More than one node for related classes can be present; they must always contain a RelatedSchemaObjectClass and Cardinality node:
<BasicSchemaObjectTypeToClass>
<RelatedSchemaObjectClass>9226486b-d7f0-4fd0-b667-da14a2a11487</RelatedSchemaObjectClass>
<Cardinality>3</Cardinality>
</BasicSchemaObjectTypeToClass>
Dat
Data added to the Data Definition. The file creates new records in the Data Definition class.
Is executed after the .class file, the Data Definition where it should be stored in.
The structural elements include the table name, column names and the created data placed inside the corresponding elements (e.g. ID of the created record and all necessary field values that should be added to the database under this ID).
Mandatory elements of the .dat file for new records of the database:
- Data Definition name: name of the table where the record will be inserted;
- Record ID: unique identifier of the record in the database table.
ID of the record must be unique and an insert of a new record with same ID but other data for the Data Definition fields is ignored:
- CreateData.dat script creates a record with a specific ID in the database.
- Further CreateNewData.dat script attempts to create a new record in the same class with the same ID but with the new data.
- Ignore data insert: new data for existing record ID is ignored, the application install/update process does not result in an error and ignored data can be traced back in the application setup log files.
.post scripts are intended for the data update operations.
.dat script example for creating a new user role:
<NewDataSet>
<SPSSecurityTypeRole>
<ID>320a6d83-6f05-ce76-1f0b-08d6e8f6ab05</ID>
</SPSSecurityTypeRole>
<SPSSecurityClassRole>
<ID>4b52c4d5-d286-e911-f280-00505690f39d</ID>
<Name>HR</Name>
<UsedInTypeSPSSecurityTypeRole>320a6d83-6f05-ce76-1f0b-08d6e8f6ab05</UsedInTypeSPSSecurityTypeRole>
<MembershipMaintenance>0</MembershipMaintenance>
<ShowInForwardAction>0</ShowInForwardAction>
<MailContentType>1</MailContentType>
</SPSSecurityClassRole>
<SPSCommonClassBase>
<ID>4c52c4d5-d286-e911-f280-00505690f39d</ID>
<UsedInType>320a6d83-6f05-ce76-1f0b-08d6e8f6ab05</UsedInType>
<TypeID>f64d3d1d-e2ab-4a43-a453-52caff9b0ccd</TypeID>
<CostCenter>816361e3-13e6-4b44-96a9-fb44c63a8e36</CostCenter>
<Location>cf060d4d-5c47-462f-b5d1-7df6c865fd91</Location>
<OU>4df735f2-b4bc-4ce8-92ee-60f40fcf5653</OU>
<Security-OU>4df735f2-b4bc-4ce8-92ee-60f40fcf5653</Security-OU>
<Security-Location>cf060d4d-5c47-462f-b5d1-7df6c865fd91</Security-Location>
<Security-CostCenter>816361e3-13e6-4b44-96a9-fb44c63a8e36</Security-CostCenter>
<Category>3</Category>
</SPSCommonClassBase>
<SPSScRoleClassBase>
<ID>4d52c4d5-d286-e911-f280-00505690f39d</ID>
<UsedInTypeSPSSecurityTypeRole>320a6d83-6f05-ce76-1f0b-08d6e8f6ab05</UsedInTypeSPSSecurityTypeRole>
</SPSScRoleClassBase>
</NewDataSet>
Del
Allows deleting data objects from the database.
- Automatically created scripts are generated from the Record Customization functionality, Configuration Packaging extension, or can be exported.
- Manually created script can delete the system data that cannot be removed via user interface due to the system restrictions, for instance, deleting a default user role.
Mandatory elements of the .del file:
- ObjectId ID: ID of the record that will be removed by the script;
- TypeID: ID of a Configuration Item the record is a part of:
<?xml version="1.0" encoding="utf-8"?>
<DeleteObjectRequest xmlns:i="http://www.w3.org/2001/XMLSchema-instance">
<Items>
<DeleteObjectRequestItem>
<ObjectId>e91a214f-0386-e911-f280-00505690f39d</ObjectId>
<TypeId>0566eada-859e-4e17-afbf-c8a98cfe0d27</TypeId>
</DeleteObjectRequestItem>
</Items>
</DeleteObjectRequest>
Bin
When the required System updates cannot be implemented with the standard schema types, the System allows executing the compiled code run by .bin scripts. This approach has no limitations and can implement absolutely any change of the System that does not align with the cases covered by the basic schema scripts.
The program class which defines the Update script has to implement the interface Matrix42.Schema.Installer.UpdateScript.
The Example of the Binary script definition:
<NativeUpdateRequest xmlns:i="http://www.w3.org/2001/XMLSchema-instance">
<Assembly>Matrix42.Maintenance.BinaryScripts.dll</Assembly>
<Type>Matrix42.Maintenance.BinaryScripts.ADDomainMigrationScript</Type>
</NativeUpdateRequest>
Post
Plain SQL storing the changes applied to the existing data created by .dat schema script type, including localization changes.
.post scripts store SQL data update statements:
--DataUpdateAccounts UPDATE [PDRNavigationItemClassBase] SET [Title] = 'User Accounts' WHERE ID = '9f4bca46-d308-e711-e79b-bc5ff41a70c0'
Starting from ESMP v.12.1.0 most cases that were covered by *.post scripts were reworked and where applicable migrated to the newly introduced schema script types, which are .update, .loc, and .merge described below. Other .post scripts that could not be classified remained as .post scripts in the system.
Update
Introduced in ESMP v.12.1.0.
Updates the existing data created by .dat schema script type. Previously this case was covered by the .post scripts but starting from ESMP 12.1.0 these operation types were separated into a stand-alone schema script type which is important for speeding up the system update process.
.update scripts store SQL data update statements:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<NewDataSet>
<PDRAudienceClass>
<ID>c2e712a8-67b7-e911-60bc-8c89a584d8da</ID>
<ConsiderRelated>0</ConsiderRelated>
<Unrestricted>1</Unrestricted>
<Configured>0</Configured>
<StrictAdminControl>0</StrictAdminControl>
</PDRAudienceClass>
</NewDataSet>
Loc
Introduced in ESMP v.12.1.0.
.loc schema script type applies all the changes related to the system localization. Separating such operation types into a stand-alone schema script type allowed speeding up the system update process.
.loc script example:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<Data>
<PDRLocalizationStringClass>
<ID>b2762cb7-66e1-41ea-983c-b225da3e79f4</ID>
<Value lcid="7"›In Bearbeitung</Value>
<Description lcid="7"></Description>
<Value lcid="10">En curso</Value>
<Description lcid="10"></Description>
<Value Icid="12">En préparation</Value>
<Description lcid="12"></Description>
<Value lcid="19">Bezig</Value>
<Description 1cid="19"></Description>
<Value Icid="22">Em progresso</Value>
<Description 1cid="22"></Description>
<Value 1cid="21">W trakcie</Value>
<Description 1cid="21"></Description>
<Value lcid="4">进行中<Value>
<Description lcid="4"></Description>
<Value lcid="16">In corso</Value>
<Description 1cid="16"></Description>
<Value lcid="25">Выполняется</Value>
<Description 1cid="25"></Description>
</PDRLocalizationStringClass>
</Data>
Merge
Introduced in ESMP v.12.1.0. The .merge script type is introduced to substitute the merge mode attribute used previously. For more details on the merge mode attribute, see the Merging changes section of this page.
Separating such operation types into a stand-alone schema script type allowed speeding up the system update process.
.merge script creates new records in the target system if they don't exist yet (standard script installation process) and updates existing ones. Merge mode does not remove any of the existing entities from the target system.
.merge script example:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<NewDataSet>
<PDRContentWidgetTemplateClassViewCustom>
<ID>3b87e5d2-18f6-45be-be6e-2595edb6f1b1</ID>
<Owner>b66041fe-e75f-ef11-6ea5-0050569016b0</Owner>
<UsedInTypePDRContentWidgetTemplateViewType>60f5b0ad-f9f0-bbf4-8da4-b4da5c409e7d</UsedInTypePDRContentWidgetTemplateViewType>
<Position>0</Position>
<Published>1</Published>
<TemplateDiff>{"Adds":[],"TypeChanges":{},"Removals":[],"Shifts":[],"ModifiedControls":[{"Id":"1b2c1f06-632f-9e36-b000-042c1e8a4e50","Properties":[{"Name":"mx-help","Value":"https://help.matrix42.com"}]}],"HasChanges":true}</TemplateDiff>
<DataModelExtentionDiff />
<PartnerCustomization>0</PartnerCustomization>
<Order>0</Order>
</PDRContentWidgetTemplateClassViewCustom>
</NewDataSet>
Schema Scripts integration
Basic principles
Schema Scripts bypass all system restrictions and data management constraints which are present in the user interface. It is highly recommended to backup the data before running any system updates in order to avoid file conflicts or data loss.
XML attributes
Bypassing SQL constraints
DisableConstraints=”true” attribute.
By default, all schema scripts of an XML format are run in DisableConstraints=”false” mode. This mode is not stated implicitly and implies that the executed scripts must follow the data consistency principle. Otherwise, the system installation or update results in an error message and the script running fails.
DisableConstraints=”true” attribute is implicitly used in those cases when it is not possible to organize and sort the scripts in a way that constraints will not be violated. Constraints include any standard SQL database constraints, for example, adding a user to a user role that does not exist yet, but will be created eventually. So the consistency principle should be respected and after all scripts have been executed the system should run in an ordinary state and align with the existing constraints.
Tend to avoid using DisableConstraints=”true” attribute as it affects the system performance as all the records from the modified table will be re-checked for data consistency and should comply with the existing constraints.
DisableConstraints=”true” usage example:
/Config/Pandora.xml:
<Script Major="02" Minor="81" Build="0028" Type="dat" Name="ServiceManagementFilters" FilePath="Pandora\02-81-0028 ServiceManagementFilters.dat" DisableConstraints="true" /> <Script Major="02" Minor="81" Build="0028" Type="dat" Name="ServiceManagementStructures" FilePath="Pandora\02-81-0028 ServiceManagementStructures.dat" /> <Script Major="02" Minor="81" Build="0028" Type="post" Name="UpdateServiceManagementStructuresAndFilters" FilePath="Pandora\02-81-0028 UpdateServiceManagementStructuresAndFilters.post" />
Defining the scripts' running order:
- Version: all three scripts have the same version.
- File type: the execution order is defined by the script type. The .post script is executed after the .dat scripts. Two of the scripts have the same .dat type;
- Disabling constraints: during the new data implementation testing the scripts may fail due to violated constraints. To make sure that both of the .dat scrips are run successfully use DisableConstraints=”true” attribute for those scripts that have dependencies. The enabled attribute assures that the ServiceManagementFilters.dat script will be run successfully in any case despite the existing constraints or dependencies on the data applied within the other ServiceManagementStructures.dat file.
Disabling transaction block
Transaction=”false” attribute.
By default, all schema scripts of an SQL format executed during installation or update process are run as a single SQL transaction. All SQL based schema scripts are grouped and executed as a single unit or block of code unless it is explicitly stated that the script should be executed separately.
Use Transaction=”false” attribute to run an SQL based script separately.
This attribute is used for those queries that cannot be run in the transaction and result in an SQL server error, for example, database migration scripts or ALTER TABLE statements.
Most of the Matrix42 schema scripts that cannot be run in a transaction are related to the full-text data indexing for the search purpose.
Merging changes
Mode=“Merge" attribute.
Explicitly stated merge mode creates new records in the target system (standard script installation process) and updates existing ones. Merge mode does not remove any of the existing entities from the target system.
Use del. scripts to explicitly declare the data that must be removed from the system.
Without this mode, the script that is run for an existing entity in the system is either ignored or fails.
This option can be used for the following types of schema scripts:
- class
- type
- pickup
- relation
- dat: starting from 12.1.0 release version instead of the
.datfile with Mode=“Merge" attribute it is suggested to use the new.mergeSchema Script type. Although the previously created.datscripts that use Mode=“Merge" attribute are still supported.
Mode=“Merge" attribute usage example:
<?xml version="1.0" encoding="utf-8"?>
<SchemaScripts>
<Script Major="2" Minor="1" Build="1" Type="class" Name="Fleet Managment_Ud_Car_create"
Mode="Merge" FilePath="install\02-01-0001 Ud_Car_create.class" />
<Script Major="2" Minor="1" Build="1" Type="relation" Name="Fleet Managment_FK_SPSUserClassBaseUd_Car_Ud_CarsOwner_create"
Mode="Merge" FilePath="install\02-01-0001 FK_SPSUserClassBaseUd_Car_Ud_CarsOwner_create.relation" />
<Script Major="2" Minor="1" Build="2" Type="dat" Name="Fleet Managment_SPSSecurityTypeRole"
Mode="Merge" FilePath="install\02-01-0002 SPSSecurityTypeRole.dat" />
</SchemaScripts>
There are cases when the merge option cannot be correctly applied due to logical or system constraints. The list of exceptions may include but is not limited to the examples listed below.
Exceptions:
- Conflicting ID and Name of the item: manually adding the attribute with the same name to the same Data Definition first on the production system and then separately in test/development environment results in different IDs for the added attribute. The merge mode of the schema script, which is exported from the test/development environment and run on the production, fails and can not be applied correctly as the ID & Name of the attribute pairs in the production and test/development are insufficient and contradictory. See also Update/Deletion Scripts section of this page for the script example.
- Changing ValueType of the Data Definition (DD) attribute: changes of the value type of a DD attribute in one system can not be merged to the other system even if the attribute has the same ID and Name in both systems. See also Optional Elements section of this page for the value type examples.
- Changing cardinality of the Data Definition (DD) in the Configuration Item (CI):
- merging a DD with mandatory cardinality in the CI to the system where the same DD as a part of the same CI has optional cardinality results in a conflict that can not be resolved.
- merging a DD with mandatory single cardinality in the CI to the system where the same DD as a part of the same CI has optional multi cardinality with several instances is not possible.
See also Type section of this page for cardinality usage example.
Ignoring SchemaScript table
Register="false" attribute
Register="false" attribute is available starting from 10.0.2 release version.
Once the schema scripts are run, and registered in the SchemaScript table, the necessary changes are applied, and the same script will never be run again. The explicitly stated Register="false" attribute allows running and applying the same schema script over and over again during the system update and data from the SchemaScript table is ignored.
Register="false" attribute usage example:
<?xml version="1.0" encoding="utf-8"?>
<SchemaScripts>
<Script Major="2" Minor="1" Build="1" Type="class" Name="Fleet Managment_Ud_Car_create"
Mode="Merge" Register="false" FilePath="install\02-01-0001 Ud_Car_create.class" />
</SchemaScripts>
Configuration Package Version
PackageVersion is automatically assigned to every schema script generated as a result of Configuration Package Export action.
PackageVersion attribute denotes the version of the Configuration Package in which a certain change to the system had been introduced. This attribute is used both in package installation and uninstallation scripts. Also, the usage of this attribute ensures the proper functioning of the Cancel option during the package installation process.
PackageVersion consists of major and minor versions of the package, for instance: PackageVersion="1.0".
PackageVersion attribute is available starting from 10.0.3 release version.
PackageVersion attribute usage example:
<?xml version="1.0" encoding="utf-8"?>
<SchemaScripts>
<Script Major="2" Minor="1" Build="2147483644" Type="del"
Name="test_PDRDataQueryType_uninstall" PackageVersion="1.0" Mode="Merge" Register="false"
FilePath="uninstall\02-01-2147483644 PDRDataQueryType_uninstall.del" />
<Script Major="2" Minor="1" Build="2147483642" Type="del"
Name="test_PDRContentWidgetTypeObjectDetails_test Preview_uninstall" PackageVersion="2.1" Register="false"
FilePath="uninstall\02-01-2147483642 PDRContentWidgetTypeObjectDetails_test Preview_uninstall.del" />
</SchemaScripts>
Redefining the script's running phase
Use the script's running phase attributes only in exceptional cases when the standard application script's logic cannot be applied.
Phases overview
Starting with ESMP 12.1.0 the overall update process is split internally into 3 phases: Preparation, Maintenance, and Post. This allowed to decrease the application's downtime, while the maintenance mode is applied only during the Maintenance phase, and Preparation and Post phases are run during the production time.
Each phase can be run separately. Thus the Preparation phase can be run, for instance, the day before the actual update while the application will keep running on the current version. The next day an update to a newer version can be applied running the Maintenance phase, implying that the system goes into the maintenance mode during the running update. The day after the Post phase can be run to finalize necessary application changes while already running on the new version and without going into the maintenance mode.
Phase types:
- Preparation Phase (Pre): data preparation phase before running the actual update. It runs in the background while the system remains operational and doesn't go into maintenance mode. This phase runs schema scripts intended to insert data in the database. Necessary database tables and data are only prepared and changes are not yet applied to the running system. The following schema script types can be processed at this point: .class, .type, .pickup, .dat, .update, .loc, .merge.
- Maintenance (Main): the actual update of the system in the maintenance mode. The data prepared in the previous phase is now copied from the temporary source to the system's database and other operations like update or delete are performed.
- Post Phase (Post): this phase is also run on a fully operational system after the previous 'pre' and 'main' phases were completed and the system is no longer in maintenance mode. At this phase, .del or .bin scripts can be run.
The system automatically defines what changes can be made in each phase based on the Schema Script types.
Phase attributes
To redefine the phase when the script should be applied use the following directives for each of the corresponding phases:
Preparation Phase: Phase="pre"
Maintenance Phase: Phase="main"
Post Phase: Phase="post"
Example: .dat script is always run in a Preparation phase, to redefine it to the Maintenance phase use Phase="main" directive
<?xml version="1.0" encoding="utf-8"?>
<SchemaScripts>
<Script Major="02" Minor="120" Build="0351" Phase="main" Type="dat"
Name="AddSearchWebOperations" FilePath="DWP\D021234567602.dat" />
</SchemaScripts>
Skipping Schema Scripts
Starting with ESMP 12.1.1, there is a possibility to manually add a condition to the Schema Script file to check if it's already been executed and skip running it again. For the configuration details, see Skipping Schema Scripts page.
Applying Schema Scripts
Install process
Before running the scripts the system installation process includes collecting and sorting all schema scripts from the /Config/ directory by their version and type:
- Run basic scripts from /ReferenceDataBaseScripts/ : db_data.xml and db_schema.sql create basic DB tables and fill them with data (are not considered as part of the schema scripts, but use the same approach);
- Custom.xml: includes reference to the basic schema scripts for adding application schema and fill out the schema with data, according to the contents of the script. All scripts from all reference files are combined in one block, sorted by version and type, and executed in the sorted sequence.
- Run the rest of the scripts from the /Config/ Directory.
- Install-Only.xml: run scripts containing demo data that is installed once and is not a part of a system data, so that it can be deleted later on, for example, demo services, default demo catalog, etc.
- Keep track of the executed scripts in the SchemaScripts database table: store version identifiers, type, file name and path, for example:
|
RowID |
Major | Minor | Build | Type | Name | FilePath | DateInstalled | Context |
|---|---|---|---|---|---|---|---|---|
| 945 | 2 | 15 | 7 | pickup | SPSActionPickupCategory |
D:\tmp\5.33.956\Matrix42 Service Store\Config\Update\Schema\U02150007007.pickup |
2019-06-01 18:21:29.773 | ConfigWizard |
| 946 | 2 | 15 | 7 | type | SPSContentTypeSeparator | D:\tmp\Martix42... | 2019-06-01 18:21:29:793 | ConfigWizard |
| 947 | 2 | 15 | 7 | dat | SPSActionPickupCategory | D:\tmp\Martix42... | 2019-06-01 18:21:29:960 | ConfigWizard |
| 948 | 2 | 15 | 7 | post | Create_usp_InstallationReport | D:\tmp\Martix42... | 2019-06-01 18:21:29:973 | ConfigWizard |
Update process
During the system update process all schema scripts are collected and sorted according to the version and type from the following sources:
- /Config/Update/Updates.xml;
- Add files from Custom.xml. This file also includes the reference to the customized schema script packages;
- Scripts from /Config/Dev/ (if present): take into account schema scripts created additionally for application development purpose;
- Run those scripts that were not executed previously (during the application setup or the latest update) and store them to SchemaScript database table.
The update process is the same for all scripts that were created as a result of standard Matrix42 platform development or customization of the standard functionality.
Install Package
The System allows installing schema scripts partially (outside of the Setup process). The tool <AppFolder>/bin/update.exe installs the scripts referenced by the specified XML:
update -schema "..\Config\Migration.xml" "..\Config"